






































![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)








































































































































































Moonshot AI Unveils Kimi-Researcher: An Reinforcement Learning RL-Trained Agent for Complex Reasoning and Web-Scale Search
The Challenge: Scaling Autonomous Agents with RL Autonomous AI agents have been at the forefront of taking computational abilities to various real-world tasks, and reinforcement learning (RL) is the key approach in agent creation. RL involves helping computational agents learn by repeatedly interacting with their surroundings, thereby improving their decision-making processes through the use of […] The post Moonshot AI Unveils Kimi-Researcher: An Reinforcement Learning RL-Trained Agent for Complex Reasoning and Web-Scale Search appeared first on MarkTechPost.

The Challenge: Scaling Autonomous Agents with RL
Autonomous AI agents have been at the forefront of taking computational abilities to various real-world tasks, and reinforcement learning (RL) is the key approach in agent creation. RL involves helping computational agents learn by repeatedly interacting with their surroundings, thereby improving their decision-making processes through the use of rewards and penalties. Training agents to self-coordinate in dealing with complex situations involving long-duration interactions, adaptive reasoning, and dynamic information retrieval is challenging. Conventional approaches, based either on supervised data or on strict workflows, cannot deliver generalizable and flexible agents that act effectively in rapidly changing situations, posing serious challenges in developing full-fledged autonomous intelligence.
Limitations of Existing Multi-Agent and Supervised Approaches
Current agent development methods are grouped into two broad categories, each with its inherent limitations. Multi-agent workflows, typically used for tackling complex tasks, allocate roles to expert sub-agents, coordinating their interactions via fixed, prompt-based protocols. As effective as they are in structured situations, these styles require significant manual adaptation to remain relevant when agents or tasks change, thereby limiting adaptability and scalability. Likewise, supervised fine-tuning processes are largely based on imitation learning, using human demonstrations to impart agents’ behaviors. This reliance necessitates heavy human labeling and creates rigidity, which is especially troublesome in long-duration, autonomous tasks or when environmental variables change unpredictably. Both approaches thereby face challenges sustaining vigorous agent functionality, pointing to a fundamental need for innovation.
Introducing Kimi-Researcher: Fully Trained with End-to-End RL
Moonshot AI researchers introduced Kimi-Researcher, a novel autonomous agent trained entirely through an innovative end-to-end reinforcement learning approach. Developed from the internal Kimi k-series model, this agent demonstrated notable proficiency in multi-turn reasoning and extensive search capabilities, navigating complex, real-world scenarios autonomously. The training method involves allowing the agent to independently explore multiple strategies, evaluating each trajectory based on outcomes, and iteratively refining the model accordingly. This holistic training bypasses reliance on manually predefined roles or extensive human-labeled demonstrations, representing a substantial shift towards scalable, autonomous intelligence systems.
Synthetic Task Design for Tool Usage and Reasoning Capabilities
Kimi-Researcher employs a comprehensive training strategy specifically designed to develop advanced cognitive capabilities and proficient tool usage. Researchers crafted a diverse, synthetic corpus, intentionally embedding scenarios that demand the effective employment of specific computational tools, such as real-time internal search functionalities, interactive text-based browsing tools, and automated code execution environments. These tailored tasks inherently require sophisticated decision-making and reasoning, ensuring the agent develops robust capabilities in orchestrating efficient tool utilization. Also, the team systematically generated and validated extensive sets of challenging reasoning-intensive tasks, including mathematical computations, logical inference scenarios, iterative search processes, and algorithmic problem-solving exercises. An automated, rigorous validation pipeline ensured the accuracy of each task, significantly improving training reliability and consistency.
Advanced RL Techniques to Optimize Training Efficiency
The researchers implemented advanced RL practices specifically tailored to the complexity of agent training. The REINFORCE algorithm, widely recognized for its effectiveness in handling sequential decision-making problems, provides a foundational training approach. Strategic methods included rigorous management of training trajectories by strictly enforcing on-policy data generation and selective handling of negative samples to prevent training degradation. Reward structures, essential to reinforcing desirable behaviors, incorporated both correctness and trajectory efficiency factors, employing gamma-decay mechanisms to reward shorter, effective exploration sequences over lengthier yet equally correct alternatives. These deliberate methodological refinements significantly fostered training stability and enhanced agent proficiency.
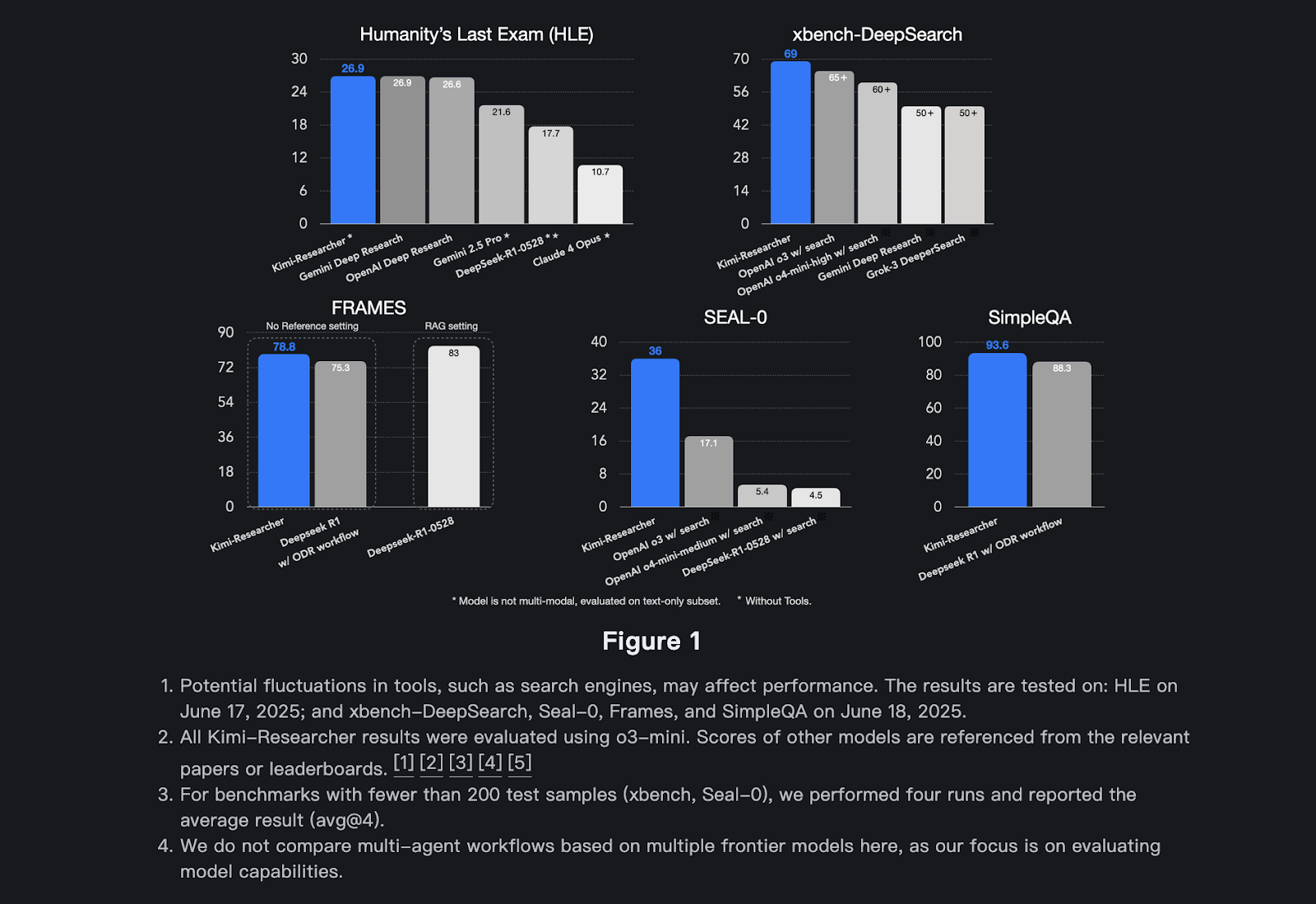
Benchmark Results: Kimi-Researcher’s State-of-the-Art Performance
Results obtained by Kimi-Researcher highlight its exceptional performance across demanding, comprehensive benchmark suites. Initially scoring a modest 8.6% on Humanity’s Last Exam (HLE), an intricate evaluation scenario challenging computational reasoning and autonomous search capabilities, Kimi-Researcher significantly improved to achieve a state-of-the-art Pass@1 accuracy of 26.9% through reinforcement training alone. The agent’s capability for sophisticated task handling was further demonstrated through a 69% Pass@1 rate on xbench-DeepSearch, a benchmark evaluating deep search and reasoning proficiency, surpassing other competitive models, such as o3 with search tools. Notably, it conducted an average of 23 reasoning steps per task and explored over 200 unique URLs, reflecting substantial autonomous reasoning and adaptive exploration capacity. The results substantiate the effectiveness of end-to-end reinforcement learning in elevating agent intelligence and autonomy, marking a considerable advancement in artificial intelligence capabilities.
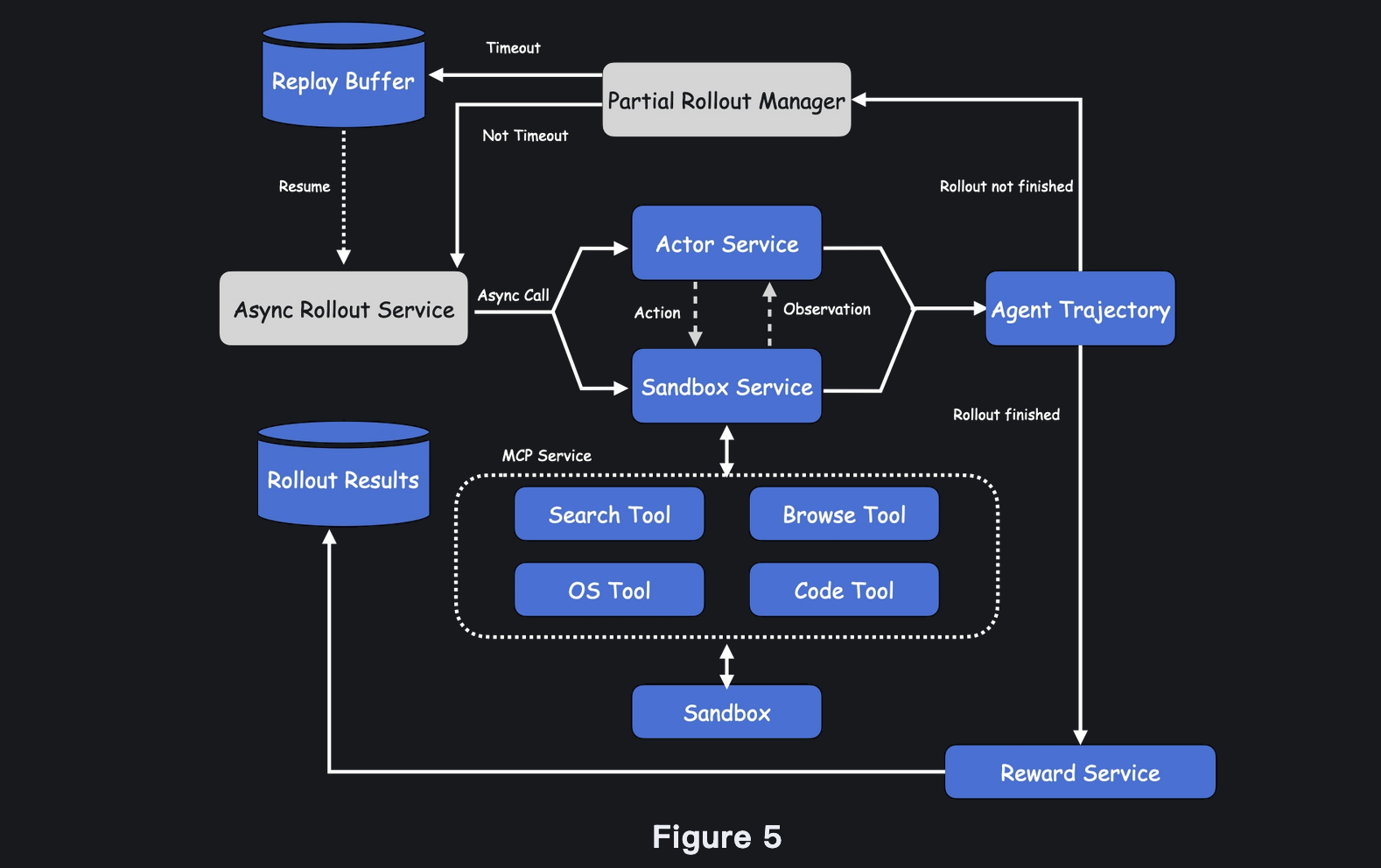
Context Management and Asynchronous Rollouts for Long Tasks
One important innovation within the training framework was a high-level context-management system that could handle the large context windows common in long-duration tasks. In the absence of context management, agent performance declined quickly under computational overload from large informational contexts. Through efficient context management, Kimi-Researcher was able to maintain effective performance through 50 iterative decision-making cycles, as well as proving increased memory management and information prioritization. Additionally, an asynchronous rollout system developed for training purposes further optimized computational efficiency, significantly reducing training times by eliminating resource idleness. The rollout system included a turn-level partial rollout mechanism that preserved incomplete long-duration tasks, permitting their continuation with updated model parameters, thereby accelerating training by at least 1.5 times compared to traditional synchronous training models.
Key Takeaways: What Sets Kimi-Researcher Apart
- Kimi-Researcher achieved substantial improvement through end-to-end RL training, notably enhancing its Pass@1 score on Humanity’s Last Exam from 8.6% to 26.9%.
- Autonomous handling of sophisticated tasks involved an average of 23 reasoning steps and explored over 200 URLs per task, underscoring considerable decision-making autonomy and adaptability.
- Introduced innovative synthetic data generation methods that ensured robust task accuracy and diversity at scale.
- Implemented sophisticated context-management methods, allowing for sustained reasoning over extensive iterations, which is crucial for prolonged tasks.
- The asynchronous rollout infrastructure substantially increased computational efficiency, achieving at least 1.5 times acceleration in training over conventional synchronous methodologies.
- Strategic RL training techniques, including selective negative sampling control and gamma-decay reward mechanisms, enhanced training stability and performance.
- Demonstrated superior proficiency on rigorous benchmark suites, establishing new performance standards in autonomous agent capabilities.
- Highlighted significant potential for scalability, adaptability, and generalization, addressing limitations of conventional supervised and workflow-dependent agent training methods.
Conclusion: Toward Generalizable and Adaptive Autonomous Agents
In conclusion, Kimi-Researcher represents a substantial progression in agentic reinforcement learning by overcoming significant constraints inherent to traditional methods. By autonomously managing sophisticated multi-turn reasoning, efficient tool usage, extensive dynamic search operations, and robust cognitive processing through end-to-end reinforcement learning, Kimi-Researcher notably surpasses previous capabilities. The methodological innovations of context management, refined reward structures, and computational optimization further demonstrate a viable path towards developing increasingly capable autonomous agents for complex real-world applications.
TL;DR:
Moonshot AI introduces Kimi-Researcher, an autonomous agent trained entirely with end-to-end reinforcement learning to tackle complex reasoning and search tasks. Unlike traditional multi-agent systems or supervised learning, Kimi-Researcher learns through dynamic interaction and self-optimization. It demonstrates significant improvements on challenging benchmarks like Humanity’s Last Exam and xbench-DeepSearch, showcasing advanced capabilities in multi-step reasoning, tool use, and exploration. Innovations include synthetic task design, gamma-decay reward shaping, context management, and asynchronous rollouts—resulting in more scalable, adaptable, and generalizable AI agents.
Check out the Technical details. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Moonshot AI Unveils Kimi-Researcher: An Reinforcement Learning RL-Trained Agent for Complex Reasoning and Web-Scale Search appeared first on MarkTechPost.





