





































![[The AI Show Episode 149]: Google I/O, Claude 4, White Collar Jobs Automated in 5 Years, Jony Ive Joins OpenAI, and AI’s Impact on the Environment](https://www.marketingaiinstitute.com/hubfs/ep%20149%20cover.png)













































































































































































NVIDIA AI Releases Llama Nemotron Nano VL: A Compact Vision-Language Model Optimized for Document Understanding
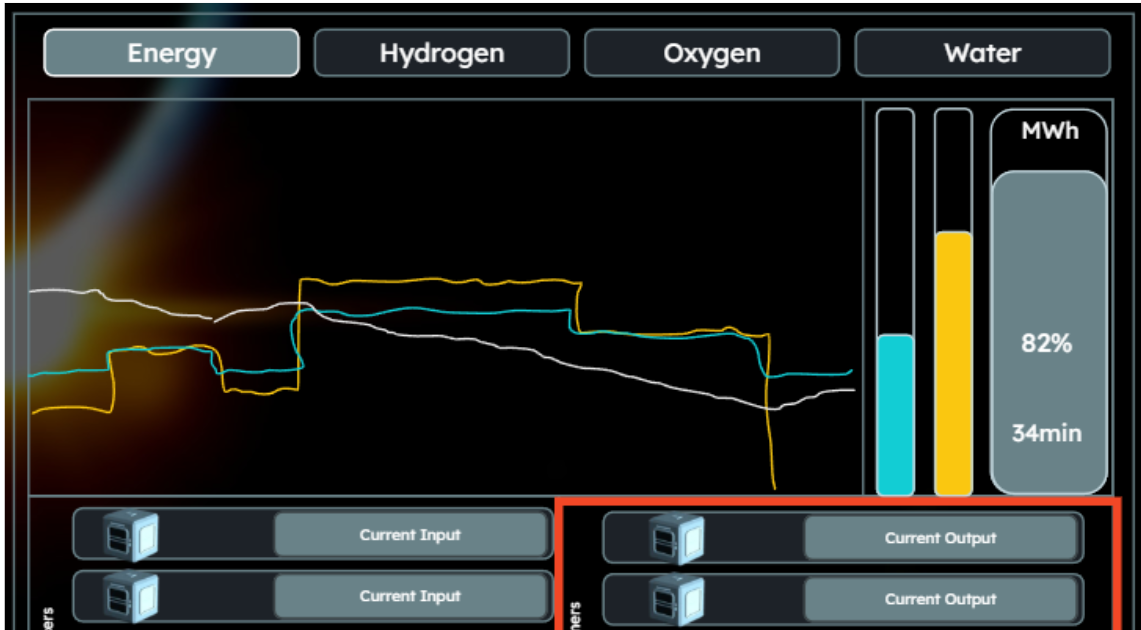
NVIDIA has introduced Llama Nemotron Nano VL, a vision-language model (VLM) designed to address document-level understanding tasks with efficiency and precision. Built on the Llama 3.1 architecture and coupled with a lightweight vision encoder, this release targets applications requiring accurate parsing of complex document structures such as scanned forms, financial reports, and technical diagrams. Model […] The post NVIDIA AI Releases Llama Nemotron Nano VL: A Compact Vision-Language Model Optimized for Document Understanding appeared first on MarkTechPost.

NVIDIA has introduced Llama Nemotron Nano VL, a vision-language model (VLM) designed to address document-level understanding tasks with efficiency and precision. Built on the Llama 3.1 architecture and coupled with a lightweight vision encoder, this release targets applications requiring accurate parsing of complex document structures such as scanned forms, financial reports, and technical diagrams.
Model Overview and Architecture
Llama Nemotron Nano VL integrates the CRadioV2-H vision encoder with a Llama 3.1 8B Instruct-tuned language model, forming a pipeline capable of jointly processing multimodal inputs — including multi-page documents with both visual and textual elements.
The architecture is optimized for token-efficient inference, supporting up to 16K context length across image and text sequences. The model can process multiple images alongside textual input, making it suitable for long-form multimodal tasks. Vision-text alignment is achieved via projection layers and rotary positional encoding tailored for image patch embeddings.
Training was conducted in three phases:
- Stage 1: Interleaved image-text pretraining on commercial image and video datasets.
- Stage 2: Multimodal instruction tuning to enable interactive prompting.
- Stage 3: Text-only instruction data re-blending, improving performance on standard LLM benchmarks.
All training was performed using NVIDIA’s Megatron-LLM framework with Energon dataloader, distributed over clusters with A100 and H100 GPUs.
Benchmark Results and Evaluation
Llama Nemotron Nano VL was evaluated on OCRBench v2, a benchmark designed to assess document-level vision-language understanding across OCR, table parsing, and diagram reasoning tasks. OCRBench includes 10,000+ human-verified QA pairs spanning documents from domains such as finance, healthcare, legal, and scientific publishing.
Results indicate that the model achieves state-of-the-art accuracy among compact VLMs on this benchmark. Notably, its performance is competitive with larger, less efficient models, particularly in extracting structured data (e.g., tables and key-value pairs) and answering layout-dependent queries.

The model also generalizes across non-English documents and degraded scan quality, reflecting its robustness under real-world conditions.
Deployment, Quantization, and Efficiency
Designed for flexible deployment, Nemotron Nano VL supports both server and edge inference scenarios. NVIDIA provides a quantized 4-bit version (AWQ) for efficient inference using TinyChat and TensorRT-LLM, with compatibility for Jetson Orin and other constrained environments.
Key technical features include:
- Modular NIM (NVIDIA Inference Microservice) support, simplifying API integration
- ONNX and TensorRT export support, ensuring hardware acceleration compatibility
- Precomputed vision embeddings option, enabling reduced latency for static image documents
Conclusion
Llama Nemotron Nano VL represents a well-engineered tradeoff between performance, context length, and deployment efficiency in the domain of document understanding. Its architecture—anchored in Llama 3.1 and enhanced with a compact vision encoder—offers a practical solution for enterprise applications that require multimodal comprehension under strict latency or hardware constraints.
By topping OCRBench v2 while maintaining a deployable footprint, Nemotron Nano VL positions itself as a viable model for tasks such as automated document QA, intelligent OCR, and information extraction pipelines.
Check out the Technical details and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter.
The post NVIDIA AI Releases Llama Nemotron Nano VL: A Compact Vision-Language Model Optimized for Document Understanding appeared first on MarkTechPost.



