





.png)






Enhancing Retrieval-Augmented Generation: Efficient Quote Extraction for Scalable and Accurate NLP Systems
LLMs have significantly advanced natural language processing, excelling in tasks like open-domain question answering, summarization, and conversational AI. However, their growing size and computational demands highlight inefficiencies in managing extensive contexts, particularly in functions requiring complex reasoning and retrieving specific information. To address this, Retrieval-Augmented Generation (RAG) combines retrieval systems with generative models, allowing access […] The post Enhancing Retrieval-Augmented Generation: Efficient Quote Extraction for Scalable and Accurate NLP Systems appeared first on MarkTechPost.



LLMs have significantly advanced natural language processing, excelling in tasks like open-domain question answering, summarization, and conversational AI. However, their growing size and computational demands highlight inefficiencies in managing extensive contexts, particularly in functions requiring complex reasoning and retrieving specific information. To address this, Retrieval-Augmented Generation (RAG) combines retrieval systems with generative models, allowing access to external knowledge for improved domain-specific performance without extensive retraining. Despite its promise, RAG faces challenges, especially for smaller models, which often struggle with reasoning in large or noisy contexts, limiting their effectiveness in handling complex scenarios.
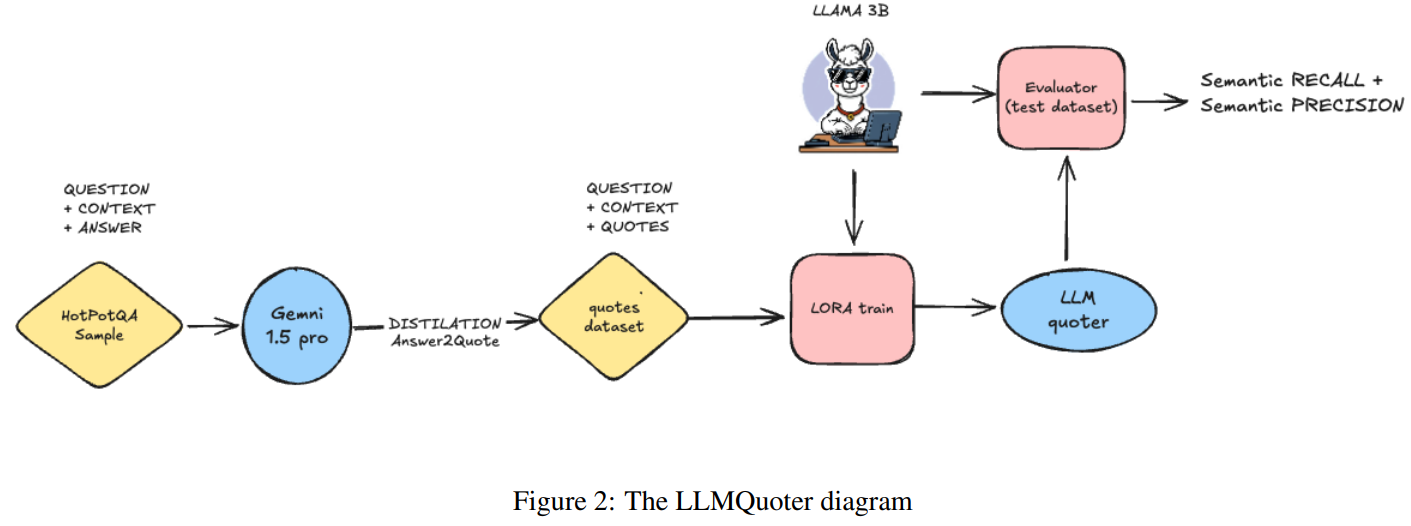
Researchers from TransLab, University of Brasilia, have introduced LLMQuoter, a lightweight model designed to enhance RAG by implementing a “quote-first-then-answer” strategy. Built on the LLaMA-3B architecture and fine-tuned with Low-Rank Adaptation (LoRA) using a subset of the HotpotQA dataset, LLMQuoter identifies key textual evidence before reasoning, reducing cognitive load and improving accuracy. Leveraging knowledge distillation from high-performing teacher models achieves significant accuracy gains—over 20 points—compared to full-context methods like RAFT while maintaining computational efficiency. LLMQuoter offers a scalable, resource-friendly solution for advanced RAG workflows, streamlining complex reasoning tasks for researchers and practitioners.
Reasoning remains a fundamental challenge for LLMs, with both large and small models facing unique limitations. While large models excel at generalization, they often struggle with complex logical reasoning and multi-step problem-solving, primarily due to their reliance on pattern replication from training data. Smaller models, although more resource-efficient, suffer from capacity constraints, leading to difficulties in maintaining context for reasoning-intensive tasks. Techniques such as split-step reasoning, task-specific fine-tuning, and self-correction mechanisms have emerged to address these challenges. These methods break reasoning tasks into manageable phases, enhance inference efficiency, and improve accuracy by leveraging strategies like Generative Context Distillation (GCD) and domain-specific approaches. Additionally, frameworks like RAFT (Retrieval-Augmented Fine-Tuning) combine reasoning and retrieval to enable more context-aware and accurate responses, especially in domain-specific applications.
Knowledge distillation plays a critical role in making LLMs more efficient by transferring capabilities from large teacher models to smaller, resource-efficient student models. This process allows compact models to perform complex tasks like reasoning and recommendation with reduced computational demands. Techniques such as rationale-based distillation, temperature scaling, and collaborative embedding distillation bridge gaps between teacher and student models, enhancing their generalization and semantic alignment. Evaluation frameworks like DSpy and LLM-based judges provide nuanced assessments of LLM-generated outputs, incorporating metrics tailored to semantic relevance and creative aspects. Experiments demonstrate that models trained to extract relevant quotes instead of processing full contexts deliver superior performance. This highlights the advantages of integrating quote extraction with reasoning for more efficient and accurate AI systems.
The study demonstrates the effectiveness of using quote extraction to enhance RAG systems. Fine-tuning a compact quoter model with minimal resources, such as 5 minutes on an NVIDIA A100 GPU, led to significant improvements in recall, precision, and F1 scores, with the latter increasing to 69.1%. Experiments showed that using extracted quotes instead of full context significantly boosted accuracy across models, with LLAMA 1B achieving 62.2% accuracy using quotes compared to 24.4% with full context. This “divide and conquer” strategy streamlined reasoning by reducing the cognitive load on larger models, enabling even non-optimized models to perform efficiently.
Future research could expand the methodology by testing diverse datasets, incorporating reinforcement learning techniques like Proximal Policy Optimization (PPO), and fine-tuning larger models to explore scalability. Advancing prompt engineering could further improve both quote extraction and reasoning processes. Additionally, the approach holds potential for broader applications, such as memory-augmented RAG systems, where lightweight mechanisms retrieve relevant information from large external knowledge bases. These efforts aim to refine the quote-based RAG pipeline, making high-performing NLP systems more scalable and resource-efficient.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.






