













OmniThink: A Cognitive Framework for Enhanced Long-Form Article Generation Through Iterative Reflection and Expansion
LLMs have made significant strides in automated writing, particularly in tasks like open-domain long-form generation and topic-specific reports. Many approaches rely on Retrieval-Augmented Generation (RAG) to incorporate external information into the writing process. However, these methods often fall short due to fixed retrieval strategies, limiting the generated content’s depth, diversity, and utility—this lack of nuanced […] The post OmniThink: A Cognitive Framework for Enhanced Long-Form Article Generation Through Iterative Reflection and Expansion appeared first on MarkTechPost.



LLMs have made significant strides in automated writing, particularly in tasks like open-domain long-form generation and topic-specific reports. Many approaches rely on Retrieval-Augmented Generation (RAG) to incorporate external information into the writing process. However, these methods often fall short due to fixed retrieval strategies, limiting the generated content’s depth, diversity, and utility—this lack of nuanced and comprehensive exploration results in repetitive, shallow, and unoriginal outputs. While newer methods like STORM and Co-STORM broaden information collection through role-playing and multi-perspective retrieval, they remain confined by static knowledge boundaries and fail to leverage the full potential of LLMs for dynamic and context-aware retrieval.
Machine writing lacks such iterative processes, unlike humans, who naturally reorganize and refine their cognitive frameworks through reflective practices. Reflection-based frameworks like OmniThink aim to address these shortcomings by enabling models to adjust retrieval strategies and deepen topic understanding dynamically. Recent research has highlighted the importance of integrating diverse perspectives and reasoning across multiple sources in generating high-quality outputs. While prior methods, such as multi-turn retrieval and roundtable simulations, have progressed in diversifying information sources, they often fail to adapt flexibly as the model’s understanding evolves.
Researchers from Zhejiang University, Tongyi Lab (Alibaba Group), and the Zhejiang Key Laboratory of Big Data Intelligent Computing introduced OmniThink. This machine-writing framework mimics human cognitive processes of iterative reflection and expansion. OmniThink dynamically adjusts retrieval strategies to gather diverse, relevant information by emulating how learners progressively deepen their understanding. This approach enhances knowledge density while maintaining coherence and depth. Evaluated on the WildSeek dataset using a new “knowledge density” metric, OmniThink demonstrated improved article quality. Human evaluations and expert feedback affirmed its potential for generating insightful, comprehensive, long-form content, addressing key challenges in automated writing.
Open-domain long-form generation entails creating detailed articles by retrieving and synthesizing information from open sources. Traditional methods involve two steps: retrieving topic-related data via search engines and generating an outline before composing the article. However, issues like redundancy and low knowledge density persist. OmniThink addresses this by emulating human-like iterative expansion and reflection, building an information tree and conceptual pool to structure relevant, diverse data. Through a three-step process—information acquisition, outline structuring and article composition—OmniThink ensures logical coherence and rich content. It integrates semantic similarity to retrieve relevant data and refines drafts to produce concise, high-density articles.
OmniThink demonstrates outstanding performance in generating articles and outlines, excelling in metrics like relevance, breadth, depth, and novelty, particularly when using GPT-4o. Its dynamic expansion and reflection mechanisms enhance information diversity, knowledge density, and creativity, enabling deeper knowledge exploration. The model’s outline generation improves structural coherence and logical consistency, attributed to its unique Concept Pool design. Human evaluations confirm OmniThink’s superior performance compared to baselines like Co-STORM, especially in breadth. However, subtle improvements in novelty are less evident to human evaluators, highlighting the need for more refined evaluation methods to assess advanced model capabilities accurately.
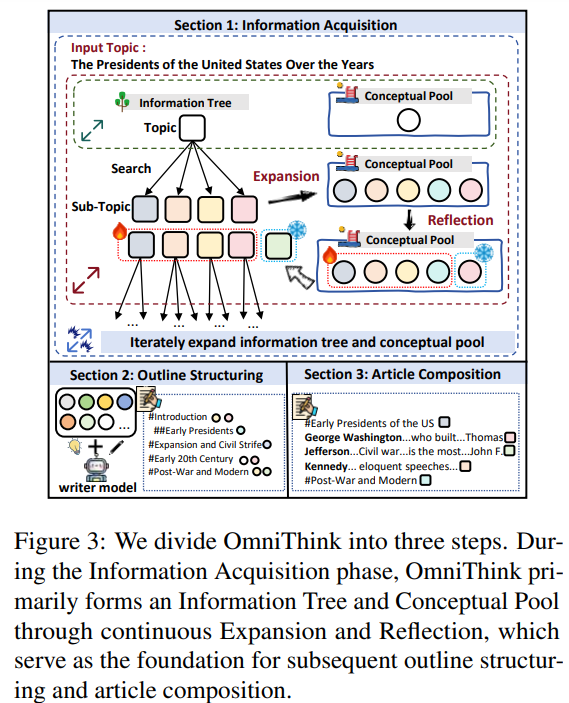
In conclusion, OmniThink is a machine writing framework that mimics human-like iterative expansion and reflection to produce well-structured, high-quality long-form articles. Unlike traditional retrieval-augmented generation methods, which often result in shallow, redundant, and unoriginal content, OmniThink enhances knowledge density, coherence, and depth by progressively deepening topic understanding, similar to human cognitive learning. As automatic and human evaluations confirm, this model-agnostic approach can integrate with existing frameworks. Future work aims to incorporate advanced methods combining deeper reasoning, role-playing, and human-computer interaction, further addressing challenges in generating informative and diverse long-form content.
Check out the Paper, GitHub Page, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.





