












AWS Athena
Amazon Athena is an interactive data analysis tool designed to process complex queries efficiently by breaking them down into simpler components, executing them in parallel, and then aggregating the results for the final output. As a serverless solution, it eliminates the need for infrastructure setup and management, so users do not have to worry about configuration, scaling, or service failures. Athena is not a database service; instead, users only pay for the queries they execute. To use it, you simply point your data stored in Amazon S3, define the necessary schema, and utilize standard SQL queries. Athena enables you to analyze unstructured, semi-structured, and structured data stored in Amazon S3. It integrates with AWS Glue to enhance the management of metadata related to the data schema in S3 through the use of crawlers. Role Of AWS Glue In AWS Athena AWS Glue helps organize your Amazon S3 data, allowing it to be queried using Amazon Athena. To start, you set up a crawler that fills your AWS Glue Data Catalog with details about the tables from the S3 data file. You direct your crawler to a data store, and it generates the table definitions in the Data Catalog. Athena Workflow When you upload a CSV or JSON file to your S3 bucket, a crawler that links to your data storage (the S3 bucket file path) goes through a list of classifiers, arranged by priority, to figure out your data's schema. It then generates metadata tables in the Data Catalog, which is a long-term metadata storage in AWS Glue that holds table definitions. When connecting a crawler to a data source, you must specify a database where the crawler will create a table based on the scanned schema from the S3 file. Crawler — A tool that connects to a data storage (either source or destination), follows a prioritization of classifiers to identify your data's schema, and then establishes metadata tables in the Data Catalog. Data Catalog — A long-lasting metadata repository in AWS Glue. It stores table definitions, job definitions, and additional control information to oversee your AWS Glue setup. Work Group — Each workgroup you create displays only the saved queries and the history of queries that ran within it, not all queries in the account. This keeps your queries distinct from others in the account, making it easier to find your saved queries and their history. Athena Queries Storage: Query results and metadata stored in S3 Prevents redundant data scanning for repeated queries Output folder in S3 must be specified for result storage Limitations: Stored procedures not supported Some DDL queries not supported Federated Queries: Enable joining results from multiple sources Sources include DynamoDB, JDBC connectors, and other AWS services Athena Cost Model Pricing: $5 per TB of data scanned Minimum charge: 10MB per query Charging Policy: Based on bytes scanned No charge for DDL (Create, Alter, Drop) and failed queries Cancelled queries charged for data scanned before cancellation Cost Optimization: Using partitions can reduce costs by minimizing data scanned This rewritten version maintains all the key information while presenting it in a more structured and easy-to-read format.
Amazon Athena is an interactive data analysis tool designed to process complex queries efficiently by breaking them down into simpler components, executing them in parallel, and then aggregating the results for the final output.
As a serverless solution, it eliminates the need for infrastructure setup and management, so users do not have to worry about configuration, scaling, or service failures.
Athena is not a database service; instead, users only pay for the queries they execute. To use it, you simply point your data stored in Amazon S3, define the necessary schema, and utilize standard SQL queries.
Athena enables you to analyze unstructured, semi-structured, and structured data stored in Amazon S3. It integrates with AWS Glue to enhance the management of metadata related to the data schema in S3 through the use of crawlers.
Role Of AWS Glue In AWS Athena
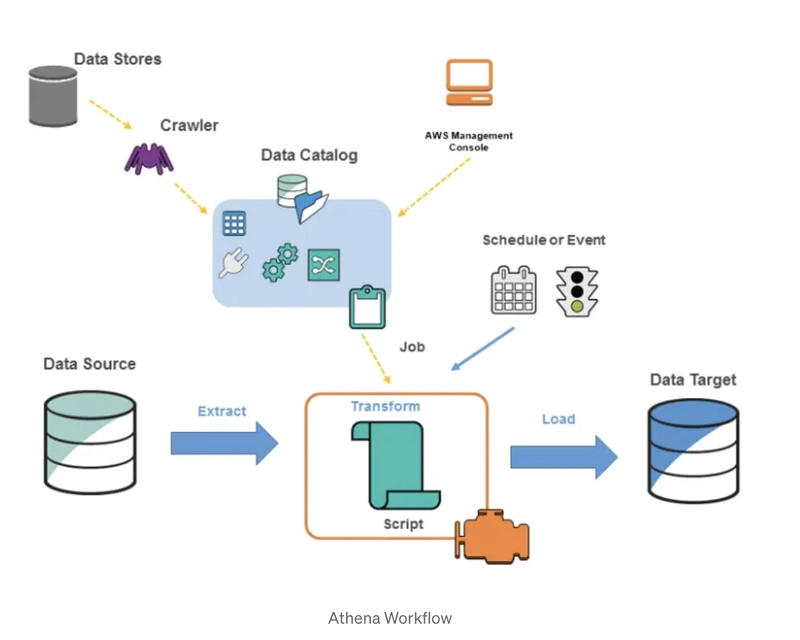
AWS Glue helps organize your Amazon S3 data, allowing it to be queried using Amazon Athena. To start, you set up a crawler that fills your AWS Glue Data Catalog with details about the tables from the S3 data file. You direct your crawler to a data store, and it generates the table definitions in the Data Catalog.
Athena Workflow
When you upload a CSV or JSON file to your S3 bucket, a crawler that links to your data storage (the S3 bucket file path) goes through a list of classifiers, arranged by priority, to figure out your data's schema. It then generates metadata tables in the Data Catalog, which is a long-term metadata storage in AWS Glue that holds table definitions.
When connecting a crawler to a data source, you must specify a database where the crawler will create a table based on the scanned schema from the S3 file.
Crawler — A tool that connects to a data storage (either source or destination), follows a prioritization of classifiers to identify your data's schema, and then establishes metadata tables in the Data Catalog.
Data Catalog — A long-lasting metadata repository in AWS Glue. It stores table definitions, job definitions, and additional control information to oversee your AWS Glue setup.
Work Group — Each workgroup you create displays only the saved queries and the history of queries that ran within it, not all queries in the account. This keeps your queries distinct from others in the account, making it easier to find your saved queries and their history.

Athena Queries
Storage:
- Query results and metadata stored in S3
- Prevents redundant data scanning for repeated queries
- Output folder in S3 must be specified for result storage
Limitations:
- Stored procedures not supported
- Some DDL queries not supported
Federated Queries:
- Enable joining results from multiple sources
- Sources include DynamoDB, JDBC connectors, and other AWS services
- Athena Cost Model
Pricing:
- $5 per TB of data scanned
- Minimum charge: 10MB per query
Charging Policy:
- Based on bytes scanned
- No charge for DDL (Create, Alter, Drop) and failed queries
- Cancelled queries charged for data scanned before cancellation
Cost Optimization:
- Using partitions can reduce costs by minimizing data scanned
- This rewritten version maintains all the key information while presenting it in a more structured and easy-to-read format.
What's Your Reaction?












