




![10 Data Science Myths Debunked [Infographic]](https://www.kdnuggets.com/wp-content/uploads/kdn-10-data-science-myths-debunked-feature.png?#)


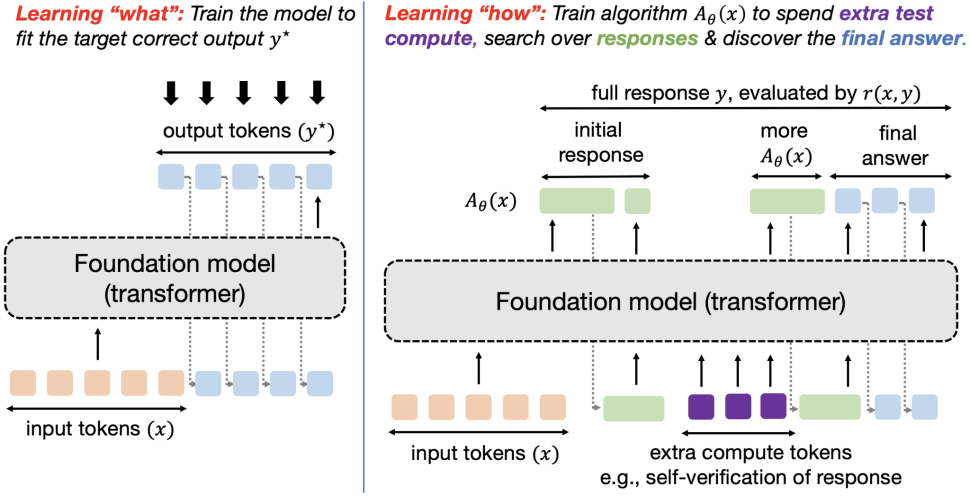





Vector search using Alibaba Cloud infererence API and semantic text
In the previous post "Elasticsearch Open Inference API Adds Support for Alibaba Cloud AI Search",It describes in detail how to use the Elastic inference API to display Ali's dense vector model, sparse vector model, re-ranking and completion. In that article, it uses a lot of English examples. However, Ali's model is more suitable for displaying in Chinese. We know that Elastic's out-of-the-box sparse vector model, ELSER, is only suitable for English. It doesn't support Chinese at the moment. Ali's sparse vector model fills this gap. Sparse vectors can be used out of the box. For many developers who are not well versed in AI, this is definitely a boon, and it uses very little resources. For more reading, see Elasticsearch's "AliCloud AI Search Inference Service" Sparse Vector According to the documentation, we use the following command to create an inference API endpoint for sparse vectors: PUT _inference/sparse_embedding/alibabacloud_ai_search_sparse { "service": "alibabacloud-ai-search", "service_settings": { "api_key": "", "service_id": "ops-text-sparse-embedding-001", "host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com", "workspace": "default" } } On top of that, we need to get the api_key from AliCloud to do so. Run the above command: Next, We can test it by doing the following (the following information is obtained from the address) POST _inference/alibabacloud_ai_search_sparse { “input": ”Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang” } The above command shows the result as: We can see from the above displayed result that it is different from our previous Elastic ELSER output. Here it should be unicode. The command above is the same as the command below: POST _inference/sparse_embedding/alibabacloud_ai_search_sparse { "input": "Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang" } Because each endpoint is automatically detected and recognized as what type of model it is when it is created by Elasticsearch, the sparse_embedding in the path above can be omitted. Dense Vectors Similarly, we use the following command to create an inference API endpoint for dense vectors: PUT _inference/text_embedding/alibabacloud_ai_search_embeddings { "service": "alibabacloud-ai-search", "service_settings": { "api_key": "", "service_id": "ops-text-embedding-001", "host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com", "workspace": "default" } } Running the above command, we can see that: We can use the following command to generate dense vectors: POST _inference/alibabacloud_ai_search_embeddings { "input": "Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang" } A dense vector is an array of floating point numbers. We can still actually scalar quantize it when we generate it, which saves memory consumption and improves the speed of the search. Completion We can even apply a big model to the search results to get a result of "completion", e.g., we use the following command to generate an inference API endpoint for completion: PUT _inference/completion/alibabacloud_ai_search_completion { "service": "alibabacloud-ai-search", "service_settings": { "host" : "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com", "api_key": "{{API_KEY}}", "service_id": "ops-qwen-turbo", "workspace" : "default" } } We can demonstrate completion with the following example: POST _inference/completion/alibabacloud_ai_search_completion { “input": ”When was Alibaba (China) Limited founded?” } This result is generated in conjunction with the big model. The big model provides a result based on the results obtained during the training of the big model. Rerank Similarly, we can generate an inference API endpoint for rerank by following the commands below: PUT _inference/rerank/alibabacloud_ai_search_rerank { "service": "alibabacloud-ai-search", "service_settings": { "api_key": "", "service_id": "ops-bge-reranker-larger", "host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com", "workspace": "default" } } In the "input" above, we have listed two documents. We can reorder these two documents using the "rerank" endpoint. Let's say the text we want to search for is "When was Alibaba (China) Limited founded?". Then "rerank" returns the result: From the above, we can see that the second document is more relevant than the first, that is, it is more relevant. RAG Applications In many cases, our organization has a lot of business data or private data being generated every now and then, and the knowledge of the big model is limited to when it is generated, so a lot of times, there

In the previous post "Elasticsearch Open Inference API Adds Support for Alibaba Cloud AI Search",It describes in detail how to use the Elastic inference API to display Ali's dense vector model, sparse vector model, re-ranking and completion. In that article, it uses a lot of English examples. However, Ali's model is more suitable for displaying in Chinese. We know that Elastic's out-of-the-box sparse vector model, ELSER, is only suitable for English. It doesn't support Chinese at the moment. Ali's sparse vector model fills this gap. Sparse vectors can be used out of the box. For many developers who are not well versed in AI, this is definitely a boon, and it uses very little resources.
For more reading, see Elasticsearch's "AliCloud AI Search Inference Service"
Sparse Vector
According to the documentation, we use the following command to create an inference API endpoint for sparse vectors:
PUT _inference/sparse_embedding/alibabacloud_ai_search_sparse
{
"service": "alibabacloud-ai-search",
"service_settings": {
"api_key": "" ,
"service_id": "ops-text-sparse-embedding-001",
"host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"workspace": "default"
}
}
On top of that, we need to get the api_key from AliCloud to do so. Run the above command:
Next, We can test it by doing the following (the following information is obtained from the address)
POST _inference/alibabacloud_ai_search_sparse
{
“input": ”Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang”
}
The above command shows the result as:

We can see from the above displayed result that it is different from our previous Elastic ELSER output. Here it should be unicode.

The command above is the same as the command below:
POST _inference/sparse_embedding/alibabacloud_ai_search_sparse
{
"input": "Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang"
}
Because each endpoint is automatically detected and recognized as what type of model it is when it is created by Elasticsearch, the sparse_embedding in the path above can be omitted.
Dense Vectors
Similarly, we use the following command to create an inference API endpoint for dense vectors:
PUT _inference/text_embedding/alibabacloud_ai_search_embeddings
{
"service": "alibabacloud-ai-search",
"service_settings": {
"api_key": "" ,
"service_id": "ops-text-embedding-001",
"host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"workspace": "default"
}
}
Running the above command, we can see that:

We can use the following command to generate dense vectors:
POST _inference/alibabacloud_ai_search_embeddings
{
"input": "Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang"
}

A dense vector is an array of floating point numbers. We can still actually scalar quantize it when we generate it, which saves memory consumption and improves the speed of the search.
Completion
We can even apply a big model to the search results to get a result of "completion", e.g., we use the following command to generate an inference API endpoint for completion:
PUT _inference/completion/alibabacloud_ai_search_completion
{
"service": "alibabacloud-ai-search",
"service_settings": {
"host" : "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"api_key": "{{API_KEY}}",
"service_id": "ops-qwen-turbo",
"workspace" : "default"
}
}

We can demonstrate completion with the following example:
POST _inference/completion/alibabacloud_ai_search_completion
{
“input": ”When was Alibaba (China) Limited founded?”
}
This result is generated in conjunction with the big model. The big model provides a result based on the results obtained during the training of the big model.
Rerank
Similarly, we can generate an inference API endpoint for rerank by following the commands below:
PUT _inference/rerank/alibabacloud_ai_search_rerank
{
"service": "alibabacloud-ai-search",
"service_settings": {
"api_key": "" ,
"service_id": "ops-bge-reranker-larger",
"host": "default-j01.platform-cn-shanghai.opensearch.aliyuncs.com",
"workspace": "default"
}
}

In the "input" above, we have listed two documents. We can reorder these two documents using the "rerank" endpoint. Let's say the text we want to search for is "When was Alibaba (China) Limited founded?". Then "rerank" returns the result:

From the above, we can see that the second document is more relevant than the first, that is, it is more relevant.
RAG Applications
In many cases, our organization has a lot of business data or private data being generated every now and then, and the knowledge of the big model is limited to when it is generated, so a lot of times, there is a lot of knowledge that the big model doesn't know. If we don't limit the answers of the big model, then it may give wrong answers and thus create illusions. In practice, we usually keep business or private data in a vector database like Elasticsearch. When searching, we first search Elasticsearch and send the results of the search to the big model as part of the prompt, which solves the hallucination problem.
First, let's create a sparse vector index:
PUT alibaba_sparse
{
"mappings": {
"properties": {
"inference_field": {
"type": "semantic_text",
"inference_id": "alibabacloud_ai_search_sparse"
}
}
}
}
Then, we write the following two documents:
PUT alibaba_sparse/_bulk
{“index”: {“_id”: “1”}}
{“inference_field”: “Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang”}}
{“index”: {“_id”: “2”}}
{“inference_field”: “Founded in 2009 and headquartered in Hangzhou, Alibaba Cloud Computing Co. Ltd (also known as Alibaba Cloud Computing Co. Ltd) is the digital technology and intelligence backbone of the Alibaba Group, providing a full range of cloud services to customers around the globe, including its own servers, elastic computing, storage, network security, database and big data. It provides a full range of cloud services to global customers, including its own servers, elastic computing, storage, network security, database and big data services."}
We perform a search with the following command:
GET alibaba_sparse/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "when was Aliyun founded?"
}
}
}
The search result above is:
Alibaba Cloud is in the first place
"Founded in 2009 and headquartered in Hangzhou, Alibaba Cloud Computing Co. Ltd (also known as Alibaba Cloud Computing Co. Ltd) is the digital technology and intelligence backbone of the Alibaba Group, providing a full range of cloud services to customers around the globe, including its own servers, elastic computing, storage, network security, database and big data. It provides a full range of cloud services to global customers, including its own servers, elastic computing, storage, network security, database and big data services."
Alibaba is in second place
"Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang"
The document containing Alibaba cloud is in the first position. This is what we call vector search.
In practice, in many cases, we sometimes want to get a unique answer, or even this answer is reasoned out, not the original document. This time we need to use the big model, that is, use the completion of the reasoning endpoint.
Let's start by doing the following search:
GET alibaba_sparse/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "Who is the legal person of Alibaba?"
}
}
}

This time only one document is listed. We use the "completion" endpoint below:
POST _inference/completion/alibabacloud_ai_search_completion
{
"input": "<|system|>
You are a knowledgeable person.
<|user|>
CONTEXT:
Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang
QUESTION:
Who is the legal person of Alibaba?
<|assistant|>"
}
In the above, we document the results of the search above "Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang" as a part of the document,and submit the search question along with it. We use the completion endpoint API to view the results:
The result will be "Alibaba's legal representative is Jiang Fang"。Obviously this is quite different from the previous approach of using "completion" without "context":
POST _inference/completion/alibabacloud_ai_search_completion
{
"input": "Who is the legal person of Alibaba?"
}
It can be understood in this way that with the results from the Elasticsearch vector database (real-time business data or private data) searched and made available to the big model, the big model can get search results that are more closely aligned to the answer based on these contexts. This is used in practice to avoid illusions!
How to build a prompt
Following the method of constructing a prompt, let's create an index of a dense vector:
PUT alibaba_dense
{
"mappings": {
"properties": {
"inference_field": {
"type": "semantic_text",
"inference_id": "alibabacloud_ai_search_embeddings"
}
}
}
}
We follow the same method for writing documents:
PUT alibaba_dense/_bulk
{“index”: {“_id”: “1”}}
{“inference_field”: “Alibaba (China) Limited was founded on March 26, 2007, legal representative Jiang Fang”}
{“index”: {“_id”: “2”}}
{“inference_field”: “Aliyun (aka: Aliyun Computing Co., Ltd.) was founded in 2009, headquartered in Hangzhou, is the digital technology and intelligence backbone of Alibaba Group, providing a full range of cloud services to customers around the world.”}}
Let's search this dense vector index alibaba_dense:
GET alibaba_dense/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "Who is the legal person of Alibaba?"
}
}
}
GET alibaba_dense/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "What kind of company is Aliyun?"
}
}
}
The results of the search above are:

Obviously, documents containing "Aliyun" are ranked first although we searched for "Alibaba".
Automatic chunking
We know that the semantic_text field can help us automatically chunk a large piece of text without us having to manually chunk it. This is one of the great benefits of semantic_text. Let's create an index called alibaba_dense_large_text:
PUT alibaba_dense_large_text
{
"mappings": {
"properties": {
"inference_field": {
"type": "semantic_text",
"inference_id": "alibabacloud_ai_search_embeddings"
}
}
}
}
We also create a large document for this index:
PUT alibaba_dense_large_text/_doc/1
{
“inference_field": ”
About Alibaba Group
Alibaba Group (Alibaba Group) is a globally recognized technology company headquartered in Hangzhou, Zhejiang Province, China, founded in 1999 by Jack Ma and his team. As a technology-driven company, Alibaba has a wide range of businesses in e-commerce, cloud computing, financial technology, digital media, logistics and other fields, and has become a key player in the global Internet industry.
Background and Early Development
The birth of Alibaba began in 1999, when the Internet was just emerging in China. With the vision of empowering small and medium-sized enterprises (SMEs) through the Internet, Jack Ma and his team launched Alibaba.com, a global wholesale marketplace. Initially, the platform provided SMEs with the opportunity to showcase their products and find international buyers, helping Chinese manufacturers reach out to the global market. After several years of development, Alibaba quickly emerged as the world's leading B2B e-commerce platform.
In 2003, Alibaba launched Taobao, a C2C platform for individual consumers, which quickly attracted a large number of users. With its “free store” model, Taobao competed with other e-commerce platforms in a short period of time and achieved success. To enhance the user experience, Alibaba launched Alipay, a third-party payment platform, in 2004, solving the trust problem of online payment, an innovation that laid the foundation for the rapid development of e-commerce in China.
Business Ecology and Strategic Layout
Alibaba has gradually built a diversified ecosystem covering e-commerce, finance, logistics and cloud computing through continuous business expansion.
E-commerce
As Alibaba's core business, e-commerce includes Taobao, Tmall and AliExpress. Among them, Taobao focuses on meeting the needs of individual consumers, while Tmall caters to brands and enterprises, providing high-quality goods and services. Global Express is dedicated to connecting overseas buyers with Chinese sellers, and is gaining influence in the international market.
Cloud Computing and Big Data
Alibaba Cloud, the core technology division of Alibaba Group, was founded in 2009 to provide cloud computing services, artificial intelligence solutions and big data technical support. Today, Alibaba Cloud has become the world's leading cloud service provider, supporting the digital transformation of enterprises.
Financial Technology
Ant Group, the parent company of Alipay, is an important part of Alibaba's fintech layout. Through Alipay, Alibaba provides users with online payment, wealth management, loans and other services, promoting the development of a cashless society in China.
Logistics and Supply Chain
Founded in 2013, Cainiao Network (Cainiao) is committed to optimizing logistics efficiency and building an intelligent logistics network with global coverage. Cainiao's technology and platform capabilities enhance the speed and reliability of e-commerce logistics services.
Digital Media and Entertainment
Alibaba has also been actively laying out in the digital media sector, including Youku, AliFilm and Shrimp Music, to promote the construction of a content ecosystem. In addition, the Group has further enriched its brand by investing in cultural and creative industries and expanding its sports business.
Internationalization and Innovation
In recent years, Alibaba has been accelerating its pace of internationalization, aiming to become a bridge between global consumers and businesses. The Group has expanded its business in markets such as Southeast Asia, Europe and North America through mergers and acquisitions and partnerships. For example, through the acquisition of Lazada, Alibaba has enhanced its e-commerce presence in Southeast Asia.
In addition, Alibaba has been actively exploring new technologies, including artificial intelligence, blockchain and the Internet of Things. The application of these technologies not only optimizes the Group's existing business, but also lays the foundation for future innovations.
Corporate Culture and Social Responsibility
Alibaba's corporate culture is based on the core mission of “making the world a business without difficulty”, and encourages employees to innovate and collaborate. Jack Ma emphasizes corporate social responsibility and advocates the use of resources for public welfare. For example, the Alibaba Foundation supports environmental protection, education development and poverty alleviation, creating long-term value for society.
Challenges and Future Prospects
Despite its remarkable achievements, Alibaba faces challenges such as intensified international competition, increased industry regulation and pressure for technological innovation. In order to maintain its leading position, Alibaba needs to continue to innovate globally while actively adapting to the regulations and cultures of different markets.
Looking ahead, Alibaba will continue to promote the integration of technology and commerce to help SMEs and consumers realize more value. At the same time, through technology development and globalization, Alibaba is expected to play a more important role in the development of the global digital economy.
Conclusion
As one of the most influential Internet companies in China and the world, Alibaba's growth history has demonstrated the profound transformation of technology on business models. Through continuous innovation and expansion, Alibaba is injecting new vitality into the global economy and creating unprecedented opportunities for countless businesses and consumers. In the future, Alibaba will continue to be driven by technology and commerce, and strive to build a more convenient and efficient digital world.
”
}
The above article is about 4500 words long.
We can view the written document in the following way:
GET alibaba_dense_large_text/_search

From above, we can see that the semantic_text field automatically chunks a very long textual document and vectorizes them separately.
We hope this article will provide you with valuable reference and inspiration in your exploration of vector search using AliCloud and Elasticsearch. In the future, as the technology continues to evolve, we expect to see more intelligent applications based on semantic understanding to land, and push the search technology to a higher level.
Harness the power of Alibaba Cloud Elasticsearch for your vector search needs. Its robust infrastructure and AI capabilities make it a top choice for businesses seeking to leverage AI for improved search outcomes.
Ready to start your journey with Elasticsearch on Alibaba Cloud? Explore our tailored Cloud solutions and services to take the first step towards transforming your data into a visual masterpiece. Click here, Embark on Your 30-Day Free Trial.





