














Sakana AI Introduces Transformer²: A Machine Learning System that Dynamically Adjusts Its Weights for Various Tasks
LLMs are essential in industries such as education, healthcare, and customer service, where natural language understanding plays a crucial role. Though highly versatile, LLMs’ challenge is adapting to new tasks. Most fine-tuning methods are resource and time-consuming. Moreover, the fine-tuning approach often results in overfitting or sacrificing general adaptability for task-specific performance. This is a […] The post Sakana AI Introduces Transformer²: A Machine Learning System that Dynamically Adjusts Its Weights for Various Tasks appeared first on MarkTechPost.



LLMs are essential in industries such as education, healthcare, and customer service, where natural language understanding plays a crucial role. Though highly versatile, LLMs’ challenge is adapting to new tasks. Most fine-tuning methods are resource and time-consuming. Moreover, the fine-tuning approach often results in overfitting or sacrificing general adaptability for task-specific performance. This is a barrier for LLMs to address dynamic new and unforeseen tasks and creates a bottleneck in the overall application.
One of the most prominent methods to address these challenges is Low-Rank Adaptation (LoRA), which updates small, task-specific matrices while freezing the rest of the model’s parameters. Although this reduces the computational cost of fine-tuning, it has limitations, such as increased sensitivity to overfitting and the inability to scale efficiently across tasks. Moreover, LoRA’s design lacks inherent compositionality, limiting its ability to integrate multiple domain-specific skills.
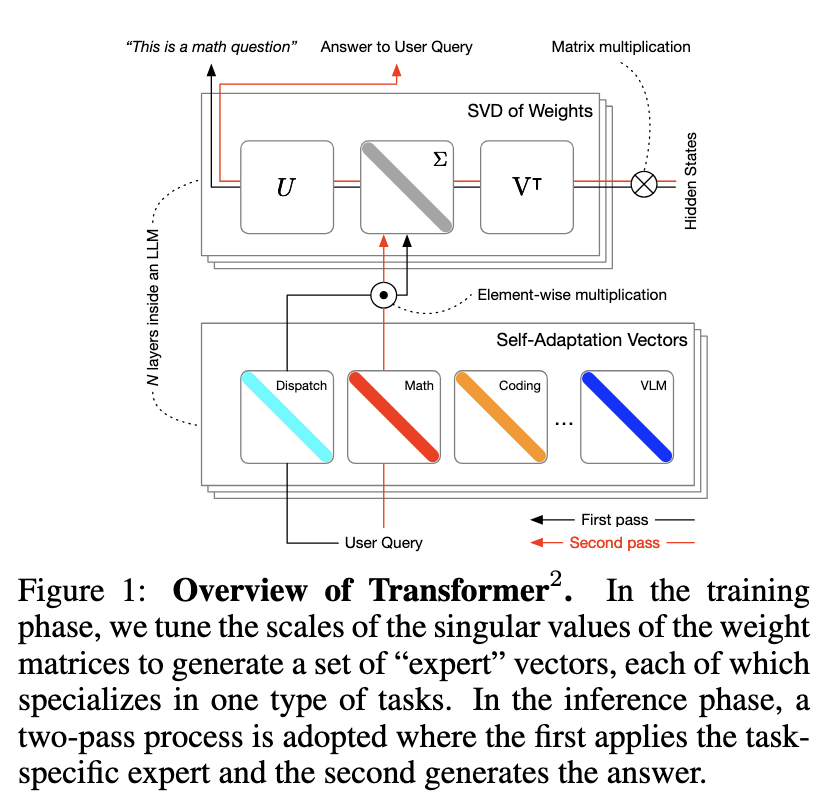
The researchers at Sakana AI and Institute of Science Tokyo introduced Transformer², a novel self-adaptive machine learning framework for large language models. Transformer² employs a groundbreaking method called Singular Value Fine-tuning (SVF), which adapts LLMs in real time to new tasks without extensive retraining. By focusing on selectively modifying the singular components of the model’s weight matrices, Transformer² enables dynamic task-specific adjustments. This innovation reduces the computational burden associated with fine-tuning, offering a scalable and efficient solution for self-adaptation.
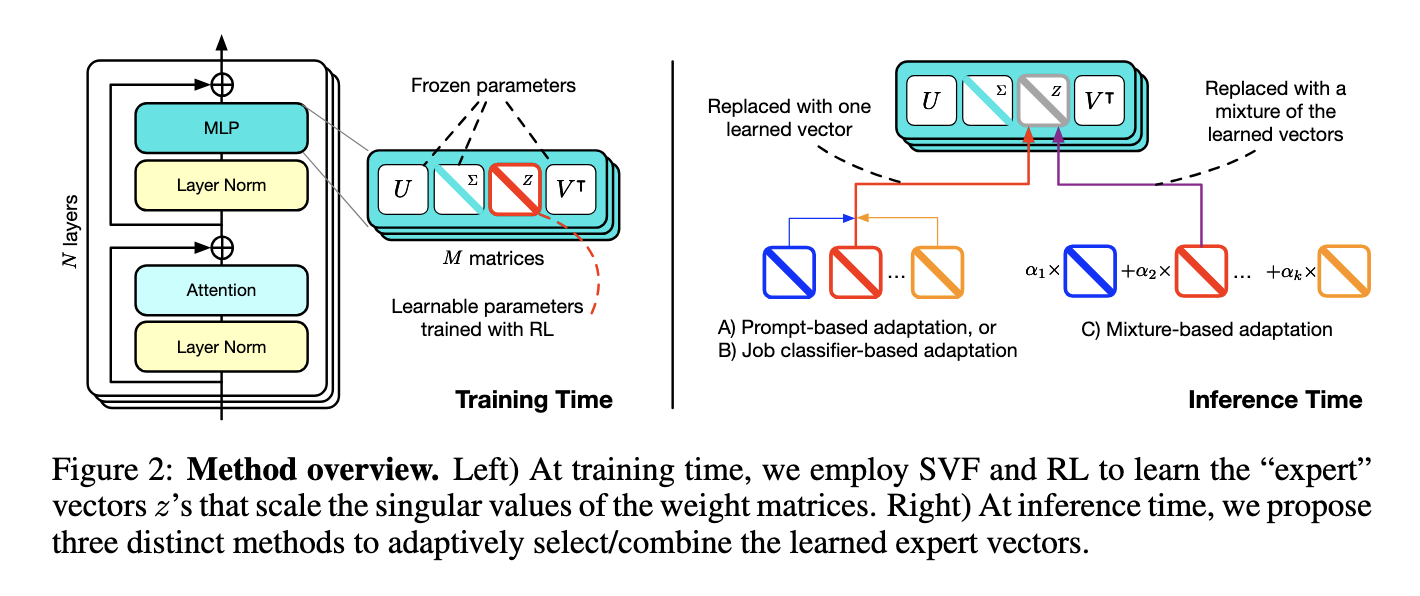
At the heart of Transformer² is the SVF method, which fine-tunes the singular values of weight matrices. This approach drastically minimizes the number of trainable parameters compared to traditional methods. Instead of altering the entire model, SVF leverages reinforcement learning to create compact “expert” vectors specialized for specific tasks. For the inference process, Transformer² works on a two-pass mechanism: the first is to analyze what the task might be and requires, and in the second, it dynamically integrates various relevant expert vectors to produce suitable behavior. Modularly, the approach ensures efficiency in addressing such a wide array of tasks through Transformer².
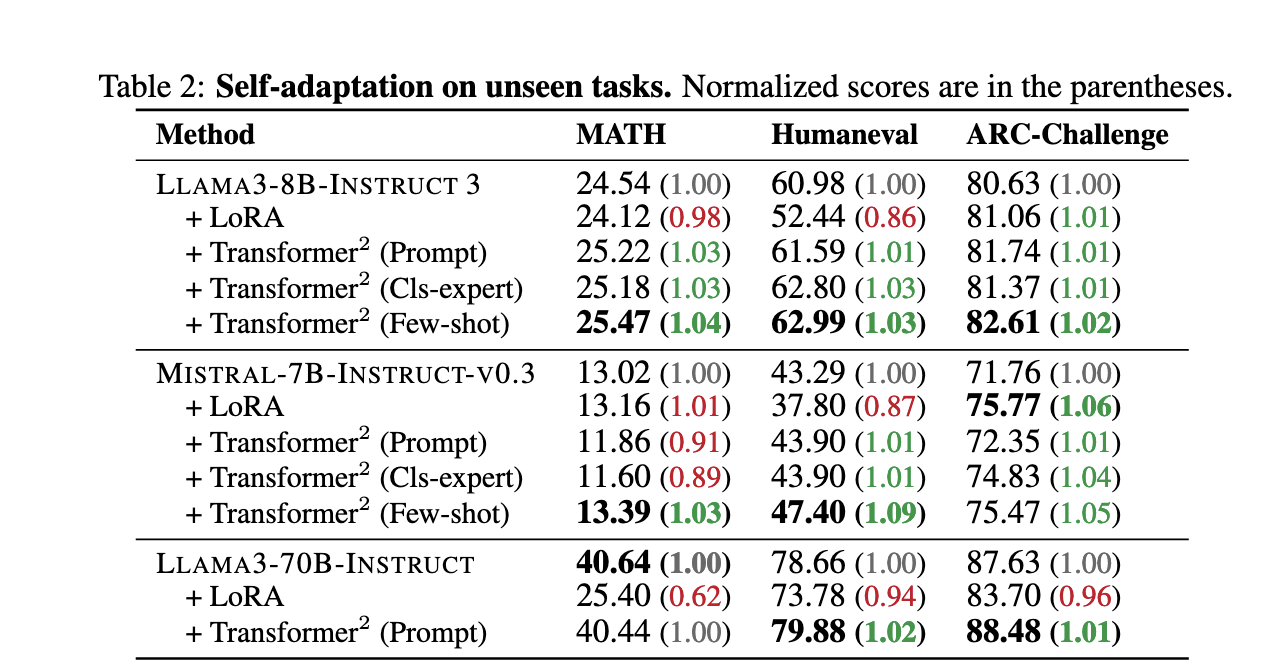
Transformer² performed outstanding performance in extensive benchmark evaluations. For instance, the framework shows improvements of over 39% compared to baselines in visual question-answering domains. In mathematics-related problem-solving, when testing was done on the GSM8K datasets, this model showed its strength by winning more than any fine-tuning method, reaching about a 4% improvement in its performance. On programming tasks under the MBPP-pro benchmark, Transformer² displayed considerable accuracy improvements for domain-specific tasks and its general performance on various types of domains. As a result, Transformer² adapted efficiently to unseen tasks like ARC-Challenge and Humaneval by either maintaining or exceeding the baseline performance metrics.
An important overall outcome was the SVF method’s efficiency. This improved training times and reduced the need for significant computational requirements as this method used fewer than 10% of the parameters required by LoRA. For example, for the GSM8K dataset, only 0.39 million parameters were needed for SVF training versus 6.82 million using LoRA to achieve higher performance. In addition, the model demonstrated good compositionality; vectors trained as an expert for one task could be reused and added together with others for a different, unrelated task, indicating the ability to scale up this Transformer² framework.

The researchers achieved this leap forward by addressing core limitations in existing methods, such as overfitting and inefficiency. By leveraging reinforcement learning, the SVF method provided principled regularization, preventing performance collapse on small datasets or narrow task domains. This allowed Transformer² to excel despite limited training data while maintaining task adaptability.
Conclusion: A research team from Sakana AI provided a scalable and efficient solution to task-specific adaptation in LLMs. Transformer², with its SVF method, is a highly significant advancement within the field that will pave the way for computationally efficient self-adaptive AI systems that are highly versatile. This approach will answer present challenges and lay a foundation for future developments of adaptive AI technologies.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.






